Appearance
知识库模块使用文档
概述
知识库模块是一个强大的企业级知识管理和智能检索系统,帮助您将各类文档(如产品手册、技术文档、FAQ问答等)转化为可被AI智能检索的知识资产。通过先进的混合检索技术,系统能够精准理解您的查询意图,快速找到最相关的内容。
核心特点:
- 支持多种文档格式:TXT、Markdown、PDF、DOCX、HTML、Excel等
- 智能混合检索:结合向量检索、全文检索和精确匹配
- 中英文双语支持:自动识别语言,智能选择分词策略
- 精准相关性:通过Rerank重排序提升结果质量
一、知识库配置
1.1 创建知识库模块
在应用设计器中,选择"知识库"模块类型,系统会自动创建知识库模块。
1.2 基本配置
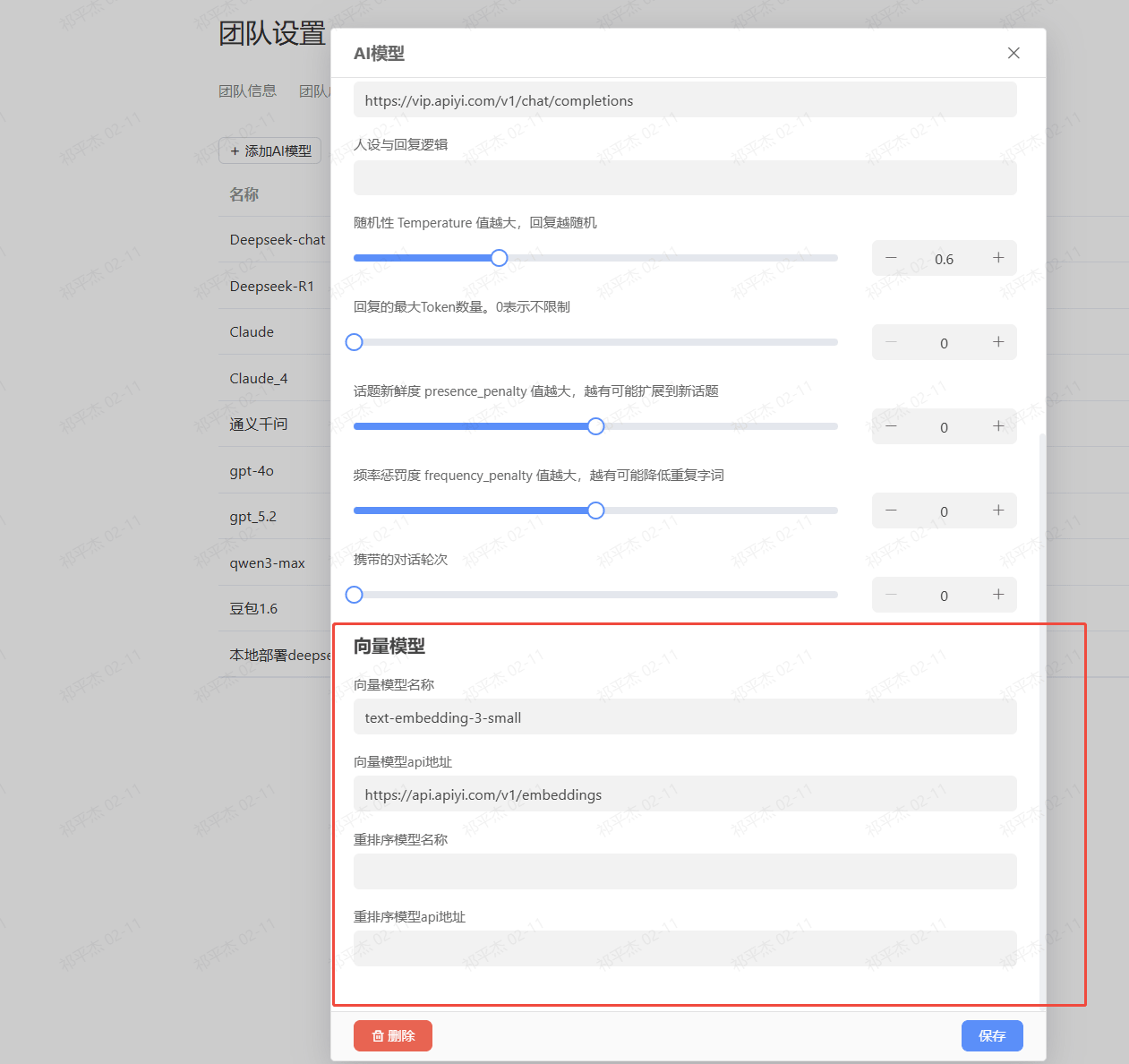
向量模型配置
向量模型用于将文本转换为数值向量,是实现语义搜索的核心。配置位置:团队设置 → AI模型配置 → 向量模型
目前常用的向量模型:
| 模型名称 | 维度 | 适用场景 | 性能特点 |
|---|---|---|---|
| text-embedding-3-small | 1536 | 通用文本检索 | 平衡性能与准确度,推荐使用 |
| text-embedding-3-large | 3072 | 高精度检索 | 更高准确度,略慢 |
| text-embedding-ada-002 | 1536 | 通用检索 | OpenAI经典模型 |
配置方法:
- 进入"团队设置" → "团队成员" → "AI模型"
- 找到"向量模型"配置区域
- 填写向量模型名称(如:text-embedding-3-small)
- 填写向量模型API地址(如:https://api.apiyi.com/v1/embeddings)
- 点击"保存"
二、检索设置
知识库提供三种检索模式,您可以根据业务需求选择最合适的策略。
2.1 向量检索
特点: 基于语义理解,能够找到意思相近但表述不同的内容
适用场景:
- 概念性查询:"什么是向量检索?"
- 意图理解:"如何提升检索准确度"
- 跨语言检索
配置项:
- 无需额外配置,选择"向量检索"即可
2.2 全文检索
特点: 基于关键词精确匹配,速度快,适合已知关键词的查询
适用场景:
- 精确关键词:"PostgreSQL配置"
- 专业术语:"RRF算法"
- 特定名称:"用户登录接口"
配置项:
- 无需额外配置,选择"全文检索"即可
2.3 混合检索
特点: 结合向量检索和全文检索的优势,使用RRF算法智能融合结果
适用场景:
- 最通用的选择,适合绝大多数检索需求
- 既需要语义理解,又需要关键词匹配
- 不确定查询类型时的最佳选择
工作原理:
- 同时执行向量检索和全文检索
- 使用RRF(倒数排名融合)算法合并结果
- 对精确匹配的内容额外加成
- 返回综合排序后的最优结果
配置项:
语义权重滑块(0.0 - 1.0)
控制向量检索和全文检索的权重比例
| 推荐值 | 说明 | 适用场景 |
|---|---|---|
| 0.5(默认) | 平衡语义和关键词 | 通用场景,推荐使用 |
| 0.3 | 偏向关键词匹配 | 已知准确关键词,需要精确结果 |
| 0.7 | 偏向语义理解 | 概念性查询,需要理解意图 |
使用建议:
- 技术文档查询:0.4 - 0.5
- 代码库搜索:0.3 - 0.4
- FAQ问答:0.5 - 0.6
- 产品手册:0.5
Rerank 模型
Rerank是一个专门的重排序模型,用于在初步检索结果的基础上,重新评估每个结果与查询的相关性,将最相关的内容排在前面。
目前常用的Rerank模型:
| 模型名称 | 适用场景 | 性能特点 |
|---|---|---|
| rerank-multilingual-v3.0 | 多语言重排序 | 支持中英文混合,准确度高 |
| rerank-english-v3.0 | 英文重排序 | 专门优化英文,速度快 |
| bge-reranker-v2-m3 | 通用重排序 | 开源模型,性价比高 |
配置方法:
- 在"混合检索"区域,开启"Rerank 模型"开关
- 在"团队设置" → "AI模型配置"中配置重排序模型
- 填写重排序模型名称(如:rerank-multilingual-v3.0)
- 系统会自动扩大候选集(通常3倍),然后使用Rerank精选结果
注意事项:
- 启用Rerank会略微增加响应时间
- 显著提升结果相关性,推荐对结果质量要求高的场景使用
- 需要先在团队设置中配置Rerank模型才能使用
Top K
设置返回结果的数量,默认为5。
| 设置值 | 适用场景 |
|---|---|
| 3-5 | 一般查询,快速获取答案 |
| 6-10 | 需要更多候选结果 |
| 10+ | 探索性搜索,不推荐设置过大 |
使用建议:
- 如果启用了Rerank,系统会自动扩大候选集为 Top K × 3
Score 阈值(相对阈值)
相对阈值过滤是一种智能的结果过滤策略,基于最高分的百分比进行过滤,而不是使用固定分数线。
工作原理:
动态阈值 = 最高分 × 阈值比例
示例:
最高分 = 0.85
阈值设置 = 0.5
动态阈值 = 0.85 × 0.5 = 0.425
只保留分数 ≥ 0.425 的结果| 推荐值 | 说明 | 适用场景 |
|---|---|---|
| 0.5 | 保留最高分50%以上的结果 | 通用场景,平衡相关性和召回率 |
| 0.3 | 保留最高分30%以上的结果 | 召回优先,希望看到更多候选 |
| 0.7 | 保留最高分70%以上的结果 | 精准优先,只要最相关的内容 |
使用建议:
- 开启Score阈值开关
- 拖动滑块调整阈值比例
- 如果结果太少,降低阈值;如果结果质量不高,提高阈值
三、文档管理
3.1 上传文档
- 进入知识库模块
- 点击"添加文档"或"上传文本文件"
- 选择文件上传
- 系统自动开始处理
支持的文件格式:
- 文本类:TXT、Markdown(.md)、HTML等
- 文档类:PDF、Word(.docx)等
- 表格类:Excel(.xlsx、.xls)、CSV等
支持的文件大小: 目前仅支持上传15M及以下大小的文档
3.2 文档类型选择
上传文档时,可以选择文档类型以获得最佳的分块效果:
| 文档类型 | 说明 | 父块大小 | 子块大小 | 适用文档 |
|---|---|---|---|---|
| 默认文档类型 | 通用文本、文章、报告 | 1000字符 | 300字符 | 产品手册、技术文章 |
| 代码文档 | 保护代码完整性 | 2000字符 | 600字符 | Java、Python代码 |
| API文档 | 按接口路径切分 | 1800字符 | 500字符 | OpenAPI、Swagger |
| Markdown | 按标题层级切分 | 1500字符 | 400字符 | 技术博客、README |
| FAQ/对话 | 问答对独立 | 600字符 | 200字符 | 客服问答 |
| 长文章 | 段落连贯性 | 1500字符 | 400字符 | 新闻、论文 |
| 数据库表 | 按表结构切分 | 2000字符 | 500字符 | 表结构、DDL |
| Excel表格 | 按Sheet切分 | 1800字符 | 450字符 | 数据报表 |
父子分块说明:
- 父块:保留完整上下文,用于理解整体语义
- 子块:提取关键信息片段,用于精准检索
- 检索时:匹配子块,返回时可以包含父块上下文
3.3 父子分块作用上下文
父块用于检索时:使用父块模式时,子块用于检索,父块用于上下文
使用场景:
查询:"如何创建数据库用户?"
匹配的子块:
"创建用户使用 CREATE USER 命令"
返回的父块上下文:
"PostgreSQL用户管理
创建用户使用 CREATE USER 命令
语法:CREATE USER username WITH PASSWORD 'password'
示例:CREATE USER admin WITH PASSWORD '123456'
注意:新创建的用户默认没有任何权限"配置方法:
段落用作上下文:
- 分段标识符:
\n\n(两个换行符,表示段落分隔) - 分段最大长度:1000字符(父块大小)
子块用于检索:
- 分段标识符:
\n(一个换行符) - 分段最大长度:300字符(子块大小)
使用建议:
- 对于技术文档,保持默认配置即可
- 对于特殊格式文档,可自定义分隔符
- 父块大小影响上下文完整性,子块大小影响检索精度
3.4 文档状态
| 状态 | 说明 |
|---|---|
| 已完成 | 文档处理成功,可以检索 |
| 处理中 | 文档正在处理,请稍候 |
| 失败 | 处理失败,请检查文档格式或重新上传 |
处理流程:
- 文档解析:提取文本内容
- 智能分块:按照文档类型进行分块
- 向量化:将文本转换为向量
- 建立索引:创建全文检索和向量检索索引
- 完成:文档可以被检索
四、使用知识库
4.1 在AI对话中使用
知识库创建完成后,AI助手中添加知识库插件:
示例对话:
用户:"如何配置Nginx反向代理?"
AI(自动查询知识库):
根据知识库中的文档,配置Nginx反向代理的步骤如下:
1. 打开Nginx配置文件 /etc/nginx/nginx.conf
2. 在http块中添加以下配置:
server {
listen 80;
server_name your-domain.com;
location / {
proxy_pass http://backend-server:8080;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
3. 重启Nginx服务:sudo systemctl restart nginx
(来源:Nginx配置手册.pdf)4.2 检索效果示例
场景1:技术文档查询
查询:"创建postgres用户"
检索结果:
1. 文档:PostgreSQL管理手册
内容:创建PostgreSQL用户使用CREATE USER命令...
相关度:0.89
2. 文档:数据库用户权限配置
内容:用户创建后需要分配相应权限...
相关度:0.76场景2:FAQ查询
查询:"忘记密码怎么办"
检索结果:
1. 文档:常见问题
内容:Q: 忘记密码怎么办?
A: 点击登录页面的"忘记密码"链接...
相关度:0.95
2. 文档:账号安全指南
内容:密码重置流程...
相关度:0.81场景3:代码查询
查询:"JWT认证实现"
检索结果:
1. 文档:认证模块代码
内容:public class JWTAuthService {
public String generateToken(User user) {...}
}
相关度:0.92五、最佳实践
5.1 文档准备建议
文档质量:
- 使用清晰的标题和段落结构
- 避免过多格式化(粗体、斜体适度使用)
- 代码使用代码块标记
- 保持文档内容完整,避免过度分散
文档组织:
- 相关内容放在同一文档中
- 使用有意义的文件名
- 技术文档选择对应的文档类型
5.2 检索策略推荐
不同场景的推荐配置:
| 场景 | 检索模式 | 语义权重 | Score阈值 | Rerank |
|---|---|---|---|---|
| 技术文档库 | 混合检索 | 0.5 | 0.5 | 开启 |
| 产品手册 | 混合检索 | 0.5 | 0.5 | 可选 |
| FAQ问答 | 混合检索 | 0.5 | 0.7 | 开启 |
| 代码库 | 混合检索 | 0.4 | 0.5 | 开启 |
| 政策文件 | 全文检索 | - | 0.6 | 可选 |
| 创意内容 | 向量检索 | - | 0.3 | 可选 |
5.3 性能优化建议
提升检索速度:
- 合理设置Top K值(5-10为宜)
- 仅在必要时启用Rerank
- 定期清理无用文档
提升检索准确度:
- 启用Rerank重排序
- 合理设置Score阈值
- 选择合适的文档类型
- 保持文档内容质量
六、常见问题
为什么查询返回结果很少或没有结果?
可能原因:
- Score阈值设置过高,过滤了大部分结果
- 文档内容与查询不匹配
- 文档还在处理中
解决方法:
- 降低Score阈值(从0.7降到0.5或0.3)
- 检查文档是否已处理完成
- 尝试使用不同的关键词查询
- 关闭Score阈值开关
中文查询效果不好?
解决方法:
- 确保文档内容质量良好
- 尝试使用混合检索模式
- 适当提高语义权重(0.6-0.7)
如何提升检索准确度?
推荐操作:
- 启用Rerank模型
- 使用混合检索模式
- 合理设置Score阈值(0.5左右)
- 选择合适的文档类型
- 保持文档内容结构清晰
如何配置向量模型和Rerank模型?
配置步骤:
- 进入"团队设置"
- 选择"团队成员" → "AI模型"
- 找到"向量模型"区域:
- 向量模型名称:text-embedding-3-small
- 向量模型API地址:(根据供应商提供)
- 找到"重排序模型"区域(如果需要Rerank):
- 重排序模型名称:rerank-multilingual-v3.0
- 重排序模型API地址:(根据供应商提供)
- 点击"保存"
什么时候应该使用父块上下文?
推荐使用场景:
- 代码查询(需要看完整函数)
- API文档(需要看完整接口定义)
- 技术教程(需要理解前后步骤)
- 长文解读(需要完整段落)
不推荐场景:
- FAQ简短问答
- 关键词查询
- 只需要片段信息的场景